Самый важный этап в проектах перехода на облачную модель организации инфраструктуры является планирование, и при выборе IaaS-провайдера необходимо учесть множество факторов, об одном из которых мы хотели бы поговорить сегодня. Речь пойдет о правильном тестировании системы хранения данных, точнее – о тестировании того слоя абстракции, который будет предоставлен вам в пользование в его роли. Это уточнение мы приводим для очерчивания рамок, в которых будет проводиться тестирование, так как нам как пользователям системы больше интересен верхний слой, с которым будут напрямую взаимодействовать наши приложения и где будут лежать наши данные.
Прежде чем переходить непосредственно к тестированию, необходимо произвести исследование существующей инфраструктуры, если речь идет о миграции. Если у вас нет возможности организовать на площадке провайдера «живое» нагрузочное тестирование, то получить объективную оценку не удастся, если вы не сможете сгенерировать максимально приближенную к продуктовой среде синтетическую нагрузку, в которой были бы учтены все нюансы работы приложения. Мы сознательно опускаем нативные средства генерации по примеру Orion Oracle – очевидно, что при наличии подобных утилит под ваше приложение, приоритет лучше отдать им, потому что никто не знает паттерны нагрузки лучше разработчиков приложения.
Основы тестирования дисковых систем
Немного теории. При тестировании мы не будем опускаться на уровень оборудования провайдера, поэтому лезть в дебри raid-penalty, выяснять, пишутся ли данные на примере wafl/zfs полным страйпом из кеша, что там с тем же кешем на уровне СХД и прочее, мы не станем. Нам эти слои не интересны, для нас важно понимать, как будет работать приложение, сможем ли мы получить необходимые показатели производительности и насколько затратно будет масштабировать эти показатели. Поэтому освежим базовые понятия, которыми мы будем оперировать:
1. IOPS
IOPS – единица измерений количества операций ввода-вывода в секунду, производимых с дисковой подсистемой по запросу приложения. Без уточняющих параметров, таких как размер блока данных, задержка, характер нагрузки и прочих, оперировать этим параметром нельзя.
2. Latency
Latency – время, за которое, по сути, совершается операция чтения-записи и приложение фиксирует этот результат. Без данного параметра опираться на голые значения IOPS не имеет смысла. Допустимый порог latency – показатель ситуативный. На практике он должен подбираться индивидуально. В нашем небольшом примере тип нагрузки на БД не особо требователен к отсутствию скачков задержки и параметр latency, к примеру равный 20, в данном конкретном случае будет допустим. Но, так как для любой БД с моделью целостности транзакций ACID для логов фактически используется queue depth == 1, то при более-менее ненулевой нагрузке та же величина latency в 20 мс будет очень узким местом.
Также нужно помнить, что слепо опираться на показания средней задержки за какой-либо промежуток времени нельзя, всегда есть риск столкнуться со скачком, который исказит итоговые результаты. К примеру, приложение сгенерировало 1000 операций за секунду, из которых 999 были выполнены за 1 мс, а одна операция по той или иной причине была завершена за 999 мс. В итоге мы имеем средний показатель задержки в 500 мс. Возможно, пример не очень корректный, так как, по сути, мы рассматриваем два пакета операций, а не 1000 и в данном случае медиана и среднее значение будут равны.
Но вывод отсюда можно сделать однозначный: нам, с некоторыми оговорками, интересно именно среднее значение по массиву и средние значения за большое количество коротких промежутков времени. Освежая школьный курс математики, взяв 5 операций ввода/вывода, при значениях задержки 1 мс, 2 мс, 2 мс, 3 мс, 189 мс медиана будет равна 2 мс. Если погрузиться в еще более глубокие размышления, то можно прийти к выводу, что и при расчете медианы мы можем столкнуться с моментом, когда после значения медианы в массиве идут запредельные значения, это тоже стоит иметь в виду. Поэтому анализировать данный параметр, как и остальные, необходимо в продолжительной динамике, особенно выбирая IaaS-площадку, где мы получаем «вершину айсберга», а вся нижележащая инфраструктура провайдера от нас скрыта.
3. Характер нагрузки
Характер нагрузки – процентное соотношение операций чтения/записи из общего количества IOPS. Если упростить, то существуют две операции – операция чтения и операция записи – и две характеристики этих операций, то есть каким образом они осуществляются со стороны системы хранения данных: последовательно (когда блоки данных считываются друг за другом, например линейно читается большой файл) и случайно (когда поток операций чтения/записи происходит с разных участков накопителей).
3. Размер блоков
Размер блоков – собственно размер блока, который используется в единичной операции чтения/записи. Без этого параметра тоже бессмысленно опираться на голые IOPS. Мы можем получить большие показатели IOPS при маленьких размерах блока, а на практике приложение может использовать иной размер и цифры IOPS радикально будут отличаться от заявленных. Поэтому необходимо уточнять, при каких параметрах были получены те или иные показания.
Тут же хочется сказать про такой немаловажный момент, как I/O Scheduler применительно к *nix системам. Это планировщики операций IO, которые производят сортировку и объединение смежных запросов, оптимизируя работу с дисковой подсистемой. Существует множество планировщиков – noop, deadline, cfq, BFQ, SIO и прочие. У каждого из них своя логика и методы обработки запросов от приложений. SIO, к примеру, отдает приоритеты маленьким, быстрым запросам, двигая в очередь более ресурсоемкие. Логика CFQ равномерно «размазывает» IO по всем процессам, дающим запрос на обращение к системе. Не будем особо заострять на этом внимание, нам важно знать одно: в тестируемой нами среде будут действовать свои планировщики на более низких уровнях абстракции (к примеру, на уровне СХД), поэтому необходимо использовать планировщик, который будет оказывать минимальное влияние на процесс IO. Наш выбор – Noop, который не управляет очередями, а только совершает merge (слияние) соседних запросов.
5. Очередь
Очередь – еще один важный показатель. Чем больше очередь, тем дольше будут выполняться запрашиваемые операции.
Практические советы
Для начала необходимо снять и проанализировать показания производительности нашего сервера БД. Для небольшого примера, я возьму свой старенький сервер с Oracle. Его единственная задача – ежедневное обновление данных, которое необходимо уложить в окно 8 часов. Пример абсолютно абстрактный, наша цель – показать саму концепцию подхода к тестированию.
Есть много подходов к мониторингу дисковой подсистемы, у себя я обычно использую связку Zabbix+iostat (Вот хорошая статья по настройке). Iostat входит в пакет sysstat, для RHEL – yum install sysstat -y.
Для нашей задачи нет особой необходимости в наглядности полученных данных, поэтому мы можем собрать информацию с iostat, что мы и сделали, получив данные за 3 подобные выгрузки, не увидев существенных различий в средних показателях. При необходимости анализируем графики Zabbix на наличие особо криминальных пиков, либо, при отсутствии последнего, графики можно построить на основании лога iostat с помощью утилиты gnuplot. Тут интересная статья с примерами скриптов по данной тематике.
Данные за период пишем в лог командой:
screen iostat -xk -t 10 | awk ‘// {print strftime(“%Y-%m-%d %H:%M:%S”),$0}’ >> iostat.log &
Тут параметры iostat выполняют следующие роли:
-x – расширяет статистику;
-k – выводит данные в килобайтах;
-t – выводит время после каждого интервала замеров;
5 – интервал, за который выводятся средние полученные значения.
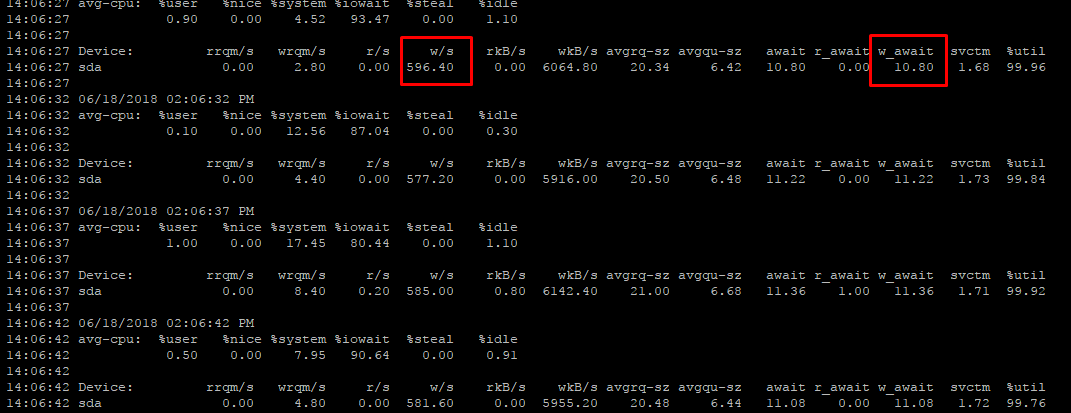
Наша система монопольно использует собственный storage, скачков за тестируемый период практически не было, очередь минимальна, поэтому опираться мы будем на следующий результат:

Давайте расшифруем вывод:
Rrqm/s(wrqm/s) – количество запросов на слияние, которые стоят в очереди на отправку к дисковой подсистеме;
w/s(r/s) – собственно наши IOPS;
rkB/s(wkB/s) – количество данных, передаваемых/считываемых за секунду в килобайтах;
avgrq-sz – среднее количество секторов, обрабатываемых за запрос (в нашем случае это ~16, при секторе в 512 = 8k, получили размер блока);
avgqu-sz – средняя длина очереди запросов;
w_await (r_await) – разделенный latency по чтению/записи;
await – это и есть средняя задержка (latency), то есть то время, за которое в итоге запрос от приложения был обработан, включая простои в очереди;
svctm – время выполнения запроса, которое не учитывает ожидание в очереди (то есть, если система справляется с нагрузкой, await будет стремиться к svctm);
%util – процент времени, затраченный на отправку/обработку операции (время, в течение которого система хранения была занята работой).
Для следующего шага нам потребуется утилита fio. Ее предназначение состоит в том, чтобы генерировать на дисковую подсистему нужную нам нагрузку. Для начала необходимо получить аналогичные показатели нагрузки нашего приложения на той же системе, где это приложение запущено, то есть подобрать такие параметры fio, которые дали бы нам такую же нагрузку на дисковую подсистему, как и само приложение, затем перенести на тестируемую площадку и начать наблюдать за результатами в динамике.
После установки fio создаем конфигурационный файл и задаем параметры нагрузки. В каждом конкретном случае подбирается свой паттерн, главное, чтобы результаты тестирования были максимально приближены к показаниям нагрузки приложения. В нашем случае получился следующий вариант:
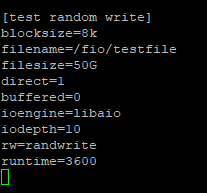
Расшифруем значения:
Blocksize – размер блока, которым мы будем оперировать во время теста.
Filename – файл, куда мы будем писать этими блоками.
Filesize – размер файла, до которого будет производиться запись. Тут надо быть внимательным: fio может забить диск, если для тестов вы установили Zabbix на тестируемую машину и собираете данные через IOSTAT, то при приближении к порогу емкости данные перестанут собираться и вы потеряете время.
Direct – крайне важный параметр, который разрешает/запрещает использовать файловый кеш. По умолчанию находится в состоянии false, что как раз задействует кеш. В нашем примере необходимо его отключить, чтобы тестирование не превратилось в тест кеша, поэтому ставим 1, что заставит fio выполнять операции в обход кеша.
Buffered – используем ли мы буферизацию (нет).
Ioengine – очень важный параметр, отвечающий за логику обработки I/O. Часто приложение использует иную механику, нежели задействуют при синтетических тестах. В моем случае приложение использует механизм AIO, который транслируется в системные вызовы через api библиотеки libaio. В вашем приложении логика может быть иная, всегда учитывайте это. К примеру, посмотреть в Oracle, используется ли AIO, можно так:
![]()
Неверное использование данного параметра полностью исказит полученный результат. Асинхронный ввод-вывод (его еще называют неблокирующим) отличается от синхронного отсутствием блокировки процесса до окончания операции I/O. При синхронном методе передачи данных пользовательский процесс отдаст данные на уровень ядра и будет ожидать от него сигнал о завершении этой операции. При асинхронном методе процесс не будет дожидаться подтверждения перед отправкой следующего запроса.
Также стоит отметить, что у механизмов ввода-вывода одного типа может быть разная реализация. К примеру, возьмем два механизма – POSIX AIO и AIO. Оба – реализация асинхронного ввода-вывода, но в первом случае асинхронность создается увеличением количества потоков, в пределах которых производятся синхронные операции, то есть глубина вашей очереди будет всегда меньше или равна количеству данных потоков. По сути, асинхронность тут иллюзорна и реализована на пользовательском уровне.
В случае AIO поток запросов идет к ядру, собирается там в очередь и направляется асинхронно на устройство ввода-вывода без фактической блокировки пользовательского процесса на операции I/O.
Важно понимать механизм, который задействован в вашей рабочей среде, и корректно перенести его на синтетический тест.
Iodepth – «глубина» очереди, по сути – количество одновременных запросов, которое может быть обработано единовременно. Это тот параметр, с которым необходимо поработать, чтобы приблизить показатели нагрузки, генерируемой fio. Изменяйте его, пока не получите результаты нагрузки приложения.
Для облегчения понимания важности глубины очереди приведем пример реализации данного параметра на хосте виртуализации vSphere. Допустим, существует хост виртуализации vSphere с подключенным к нему LUN и глобальным показателем глубины очереди (DSNRO) в 32. Пока на данном LUN одна виртуальная машина, ей доступна вся глубина очереди, но стоит создать дополнительную виртуальную машину, как количество обрабатываемых операций от двух виртуальных машин будут суммарно ограничены глубиной в 32 одновременных запроса. Это еще одна причина, по которой при выборе IaaS-площадки необходимо проводить долгосрочные тесты.
Rw – характер нагрузки, в моем случае – это случайная запись. Также существуют read/write (последовательные чтение/запись) и randread (случайное чтение).
Runtime – лимит выполнения тестирования по времени.
Numjobs – количество рабочих процессов, выделенных на обработку I/O. Для каждой БД логика выделения потоков своя. К примеру, для Oracle RDBMS существует параметр db_writer_processes, который явно указывает количество выделенных потоков, которые будут обрабатывать ввод-вывод.
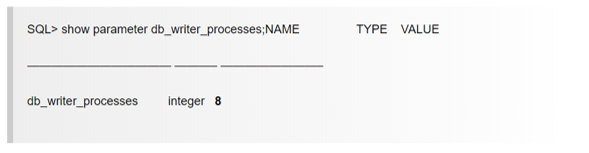
К примеру, в Oracle при подобном значении fio job файл будет выглядеть так:
[test random write]
blocksize = 8k
filename=/fio/testfile
filesize=50G
direct=1
buffered=0
ioengine=libaio
iodepth=10
rw=randwrite
runtime=3600
numjobs=8
Для MySQL – не более 4 потоков I/O, если речь идет о storage engine InnoDB (в более свежих версиях обещали увеличить).
Для PostgreSQL – зависит от плана запроса. Те или иные участки выполнения плана могут провоцировать ввод-вывод с различной параллельностью. И так далее.
Fio имеет обширнейшие возможности, настоятельно рекомендуем ознакомиться с ними поближе. Вы можете варьировать процентное соотношение характера нагрузки, запускать несколько заданий, нужное количество потоков и другие. Например, чтобы создать гибридную нагрузку (чтение/запись), в конфигурационный файл просто добавляется дополнительный блок на чтение:
[random write]
blocksize=8k
filename=/fio/testfile
filesize=50G
direct=1
buffered=0
ioengine=libaio
iodepth=10
rw=randwrite
runtime=3600
nubjobs=4
[random read]
blocksize=8k
filename=/fio/testfile
direct=1
buffered=0
ioengine=libaio
iodepth=10
rw=randwrite
runtime=3600
numjobs=4
На выходе работы fio мы получаем примерно следующее:
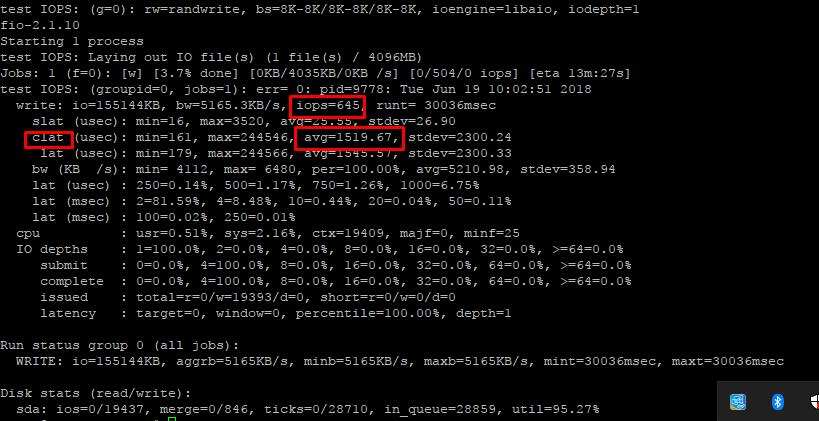
Необходимо уточнить, что в данном случае используется один поток, что может быть некорректно для вашей ситуации. Вам необходимо определить в job-файле описанный выше параметр numjobs. Тут два варианта:
- Необходимо задействовать аналогичные по отношению к рабочей среде параметры CPU там, где необходимо определить максимальную пропускную способность.
- Необходимо учесть логику и реализацию параллельности для вашей БД.
Теперь нам осталось всего лишь наложить нагрузку на площадку провайдера и посмотреть, как будет вести себя их хранилище. Помните, что максимально приближенный к продуктовым реалиям результат вы получите, только максимально приблизив конфигурацию арендуемых мощностей к своим рабочим системам (CPU, RAM, OS, filesystem, IO mechanism etc).
Запускаем fio на площадке провайдера с конфигурационным файлом, который мы получили при тестировании на своей системе. Вы можете наблюдать за тестированием в реальном времени в запущенном параллельно IOSTAT либо писать его в лог:
Посмотрим на полученный результат:

IOPS при оперировании блоками по 8K получили равными 749 при средней задержке clat (не путать с соседним параметром, где slat – время, за которое ушел запрос от операционной системы к СХД) 13274.95/1000=13.2 мс.
Далее смотрим графики за тестируемые промежутки.


В нашем случае цифры приемлемые, осталось продлить тест до необходимой уверенности в стабильности минимальных показателей (субъективный срок, который определяется самостоятельно: кому-то достаточно 2-3 дней, кому-то не хватит и месяца).
Также необходимо поговорить о нескольких фундаментальных вещах, которые обязательно следует учесть при выборе IaaS-провайдера и формировании необходимого SLA:
1. Показатель IOPS в SLA практически ничего не значит. Характер вашей нагрузки может разительно отличаться от попугаев, которые демонстрирует провайдер (этим также грешат практически все производители СХД). Необходимо уточнить, при каких условиях и какой нагрузке получены результаты, и просить предоставить гарантированные показатели, основанные на вашей рабочей нагрузке.
2. Зачастую IaaS-провайдеры указывают максимальные значения IOPS и минимальные latency и опускают пороги, до которых эти показатели могут деградировать. Данный подход может подвести к ситуации, что при создании тестовой среды вам будет предложен так называемый lab queen, который будет выдавать указанные провайдером максимумы, либо в процессе эксплуатации вы столкнетесь со стабильно слабыми показателями быстродействия, которые, к примеру, только в определенные часы будут выдавать указанные показатели. Вам необходимо договариваться об уровне SLA по результатам тестирования, чтобы ваш пик нагрузки пришелся на минимально гарантированные провайдером показатели, если ваши требования к данным параметрам действительно критичны для бизнеса. Не сочтите за антирекламу, пример данного подхода можно посмотреть тут. Вы можете заметить, что указаны только МАКСИМАЛЬНЫЕ значения.
3. Необходимо разворачивать тестовую среду, максимально приближенную к продуктовой. Только ваше приложение позволит составить реальную картину и прогнозировать будущее использование арендуемых мощностей. Если такой возможности нет, следует максимально приблизить синтетическую нагрузку с получаемыми в продуктовой среде показателями, для этого надо учесть несколько моментов:
- Тестирование должно проходить на OC и файловой системе идентичной той, которое в данный момент использует ваше приложение.
- По возможности используйте нативные приложения для генерации рабочей нагрузки.
- Необходимо учитывать роль CPU в операциях ввода-вывода, знать количество потоков/процессов (что порой крайне затруднительно и непрогнозируемо), которые задействованы в генерации запросов на IO и не допускать ситуации, когда количество «арендованных CPU» меньше количества этих процессов.
- Необходимо учитывать роль IO Scheduler и по возможности использовать тот, который оказывает минимальное влияние на очередь.
- Мы не знаем, какие механизмы задействованы для обеспечения QOS и распределения ресурсов ниже предоставленной нам «услуги». Мы не видим графики загрузки СХД, поэтому любые тестирования необходимо проводить на максимально большом промежутке времени, чтобы получить более объективную картину.
4. Необходимо максимально изучить приложение для генерации максимально приближенной синтетической нагрузки. Можно учесть все мелочи: одноблочные/многоблочные чтения, разделения на потоки, загрузка CPU, механизмы IO, но по возможности необходимо ВСЕГДА производить тестирование тем приложением, которое будет генерировать нагрузку в рабочей среде. Более точных показателей вы не получите, а ошибка может обойтись дорого.